郑重说明,这一篇以及后序的博文我都尽量少贴代码,而是尽我的描述能力之所能把我自己的理解和思考的过程总结表达出来,千万别指望着看完我的某一篇博客就能彻底地理解某一个知识点,至少我是没有这样的表达能力的。想要知其所以然,唯一的途径就是:
Read the F**king source code
正如侯捷在某一本书的扉页中写道的那样:
代码面前,没有秘密
以上
为什么要有 slab
一般来说,一个新东西的产生总是为了解决某一个现有的问题的。那么,slab 是为了解决什么问题呢?我们知道,在 Linux 内核中的内存管理是使用伙伴系统 (Buddy system),但是这个系统有一个问题就是,它的最小单位是页,即 PAGE_SIZE ,在 x86 架构中这个常数一般是 4k 。但是很多情况下我们要分配的单元大小是远远小于 4k 的,如果使用伙伴系统的话,必定是会产生很大的浪费的。所以,一个粒度更加小的分配器呼之欲出,slab 就是为了解决这个小粒度内存分配的问题的。
如何解决以及结构组织
既然 slab 分配器已经定下了这样的一个目标,那么它的策略是什么呢? 答曰,slab 分配器是基于所谓“面向对象”的思想,当然,这里的“面向对象”跟 C++ 和 Java 等的“面向对象”是不一样的。这里的“面向对象”更加确切的说法是“面向对象类型”,不同的类型使用不同的 slab ,一个 slab 只分配一种类型。而且,slab 为了提高内核中一些十分频繁进行分配释放的“对象”的分配效率, slab 的做法是:每次释放掉某个对象之后,不是立即将其返回给伙伴系统(slab 分配器是建立在伙伴系统之上的),而是存放在一个叫 array_cache 的结构中,下次要分配的时候就可以直接从这里分配,从而加快了速度。
这里必须明确几个概念,说明如下:
缓存(cache) : 这里的缓存只是一个叫法而已,其实就是一个管理结构头,它控制了每个 slab 的布局,具体的结构体是 struct kmem_cache 。(注意,虽然现在几乎所有的书或者博客都将这一个结构称为“缓存”,不过我觉得在这里称为“管理结构头”是更为合适的,所以下文中统一将“缓存(cache)”称为“管理结构头”。)
slab: 从伙伴系统分配的 2^order 个物理页就组成了一个 slab ,而后续的操作就是在这个 slab 上在进行细分的,具体的结构体是 struct slab 。
对象(object) : 上面说到,每一个 slab 都只针对一个数据类型,这个数据类型就被称为该 slab 的“对象”,将该对象进行对齐之后的大小就是该“对象”的大小,依照该大小将上面的 slab 进行切分,从而实现了我们想要的细粒度内存分配。
per-CPU 缓存:这个就是上面提到的 array_cache ,这个是为了加快分配,预先从 slab 中分配部分对象内存以加快速度。具体的结构体是 struct array_cache,包含在 struct kmem_cache 中。
具体的结构如下图:
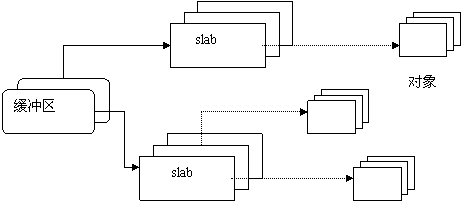
还有,我们在用户态编程的时候,需要分配内存的时候,一般都是使用 malloc() 函数来实现。那么在内核态编程中,如果我们要分配内存,而且又没有必要使用上面的基于某个特定对象的,内核给我们提供了一个类似 malloc() 的接口—— kmalloc() 。值得注意的是,其实 kmalloc() 也是基于 slab 分配器的,只不过它所需要的管理结构头已经按照 2^n 的大小排列事先准备好了而已,这个管理结构体数组是 struct cache_sizes malloc_sizes[] 。
还有,每个“对象”的缓存被组织成一个链表——cache_chain,然后每个缓存的 slab 被组织了三个不同的链表——slab_full,slab_partial和 slab_free,这三个链表有何不同应该可以见名知意,就不赘述了。
然后,你可能就会发现了,在对象那一点,很可能出现一种情况,那就是 slab 的大小跟 object 的大小不整除,也就是说有不足于一个 object 的大小的空间剩余,怎么办,浪费掉吗?肯定不是!内核很好地利用了这些剩余的空间,提出了“缓存染色(cache coloring)”的概念。当然,这里的染色不是真的去染成红绿蓝等颜色,这只是一种说法而已。具体地将,就是让每个缓存的 slab 在页的起始位置有不同的偏移,以缓解缓存过热的问题。注意,这里提到的“缓存过热”中的“缓存”是真的 CPU 的物理缓存。具体的我后面会详细说明,这里只是综述一下。
初始化—— kmem_cache_init()
想要让 slab 分配器工作起来,必须进行一系列的初始化。不过这里存在一个“鸡生蛋蛋生鸡”的问题。我们前面说过,每个缓存需要一个管理结构头,而建立缓存的实质就是分配一个管理结构头 struct kmem_cache 来描述 slab 的布局,以指导后续的分配行为,这个建立缓存的过程是用函数 kmem_cache_create() 来实现的,这里这是点一下,下面会详细说明。很明显这个管理结构头的大小小于一页,那么是十分适合使用 slab 分配器进行分配的,但是问题是此时 slab 分配器还没有初始化完成,怎么办?内核的做法是直接静态分配一个 struct kmem_cache 类型的变量——cache_cache(不得不说,这个变量名起得真好!),然后呢,整个初始化的过程分为六步:
初始化 struct kmem_cache 变量 cache_cache 。该变量之所以重要,是因为它是以后所有的对象的管理结构头的管理结构头,专业一点的话可以称作是“元管理结构头”,然后上面提到的 array_cache 和三个链表 kmem_list3 都是这个结构体里面的成员,初始化也都是静态分配的,对应的静态变量分别是 initarray_cache 和 initkmem_list3 。
建立 kmalloc() 的 struct array_cache 对应大小的管理结构头。为什么要进行这一步呢,因为下面的步骤是要完整地建立其 kmalloc() 支持的所有 2^n 大小的管理结构头,完成这一步就相当于 kmalloc() 完全可用了。但是每个管理结构头都必须要 struct array_cache 和 struct kmem_list3 这两个辅助管理结构头,就必须要建立这两个对应大小的 kmalloc() 的管理结构头以便能够使用 kmalloc() 动态分配!这里之所以要提到动态分配是因为在给 struct array_cache 对应大小建立 kmalloc() 的管理结构头的时候,其自己的 struct array_cache 和 struct kmem_list3 也是静态分配的,所以后续将会把它们使用动态分配的空间替换掉。
建立 kmalloc() 的 struct kmem_list3 对应大小的管理结构头以及剩下的 2^n 对应大小的管理结构头。第二点已经说明过了,就不重复了。
(其实包括第五步)此时 kmalloc() 已经可用了,所以如上面所说要使用 kmalloc() 分配的动态内存去替代前面所有的静态内存,需要替换的对象有:cache_cache 的 struct array_cache ,struct array_cache 对应大小的 kmalloc() 的管理结构头的 struct array_cache 和 struct kmem_list3,以及 struct kmem_list3 对应大小的 kmalloc() 的管理结构头的 struct kmem_list3 。
重新调整各个管理结构体的 struct array_cache 中的 entry[] 的数目。
然后这里有一个问题就是,内核是如何知道当前是属于哪一个阶段呢?为了解决这个问题,内核使用了一个枚举变量 g_cpucache_up ,其接受的变量范围有:NULL , PARTIAL_AC , PARTIAL_L3,PEARLY , FULL 。当第二步完成的时候,标记为 PARTIAL_AC ,此时意味着以后的 struct array_cache 都可以使用 kmalloc() 分配了;当第三步完成的时候,标记为 PARTIAL_L3 ,此时意味着以后的 struct kmem_l3 都可以使用;当第四和第五步完成的时候,标记为 PARTIAL_EARLY ,此时意味着 kmalloc() 已经支持所有其支持的 2^n 大小的内存分配了。
然后有一个很重要的点就是,如果你读过 mm/slab.c 的源代码,你就会发现,在建立 struct array_cache 的管理结构头和为 kmalloc() 各个管理结构头的 struct array_cache 的时候,**内核使用的是 struct arraycache_init 而不是 struct array_cache **,这究竟是怎么一回事?其实这是很有讲究的,且听我慢慢到来。
其实 struct initarray_cache 的完整结构是这样的:
struct arraycache_init {
struct array_cache cache;
void *entry[BOOT_CPUCACHE_ENTRIES];
};从上面的结构可以看出,struct arraycache_init 就只是比 struct array_cache 多了一个 void * 的数组而已,这个究竟有什么区别呢?诶,别着急,我们再来看一下 struct array_cache 的结构就清楚了:
struct array_cache {
unsigned int avail;
unsighed int limit;
unsigned int batchcount;
unsigned int touched;
spinlock_t lock;
void *entry[];
};联系上文我提到 Per-CPU 的时候说过,为了加快速度将 slab 的一部分内存分配到 array_cache ,而事实上就上面我们看到的 struct array_cache 的结构,只是有一个 void * 的数组而已,而且是个伪数组,并没有数组项。其实细想这是一种十分优美的实现方法。因为各个管理结构头所需要的“一部分内存”是不一样的,这样就保证了一个通用性,每次要访问 array_cache 里面的内存的时候,只需要进行 array_cache->entry[下标] 就可以了。然后我们再来解决上面提到的 struct arraycache_init 的问题。内核静态分配了这样的一个 struct arraycache_init 的静态变量:
static struct arraycache_init initarray_cache __initdata =
{ {0, BOOT_CPUCACHE_ENTRIES, 1, 0} };对照结构体的成员我们发现,struct array_cache 的 batchcount 被被赋值为 BOOT_CPUCACHE_ENTRIES ,这个 batchcount 是什么来头呢?这个变量就是控制着我们上面提到的“一部分内存”的具体量了。更重要的是,我们可以看到,struct arraycache_init 多出来的那个 void * 数组的个数,就是 BOOT_CPUCACHE_ENTRIES 。也就是说,struct array_cache 的管理结构头的 struct array_cache 里面的 entry 的真正空间就在这里了。
提到这里的话,那么初始化的第六步就可以彻底地理解了:为每个 kmalloc() 的管理结构头的 array_cache 重新调整 entry 的个数,具体的函数调用是 enable_cpucache()->do_tune_cpucache()->alloc_arraycache() 。
创建管理结构头—— kmem_cache_create()
因为在初始化的过程中已经静态分配了管理结构头的管理结构头—— cache_cache,所以可以直接使用 kmem_cache_alloc() 给提供的对象建立其自己的管理结构头 struct kmem_cache ,而这个函数的作用也是如此。除了如此外,这个函数还有一个十分重要的功能就是创建 slab 的布局,即—— 应该占用页帧的阶数,slab 管理头应该在页内还是页外,剩余空间是多少,染色的个数,染色的大小(这两个说法在这里可能有点奇怪,不过等我们提到“染色”的时候就清楚了)等,具体的函数调用是 calculate_slab_order()->cache_estimate() ,过程比较简单,就不提了。
最后调用 enable_cpu_cache() 配置 struct array_cache 和 struct kmem_list3 ,这一步类似于我们在初始化那一节提到的第六步,也就不在重复了。
最后建立的管理结构头加入到 cache_chain 这个链表。
分配内存—— kmem_cache_alloc()
kmem_cache_alloc() 这个函数进过多层的封装,最终调用的是 ____cache_alloc() ,kmalloc() 也是如此。我们先来看一下这个函数:
static inline void * ____cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
void *objp;
struct array_cache *ac;
check_irq_off();
ac = cpu_cache_get(cachep);
if (likely(ac->avail)) {
STATS_INC_ALLOCHIT(cachep);
ac->touched = 1;
objp = ac->entry[--ac->avail];
} else {
STATS_INC_ALLOCMISS(cachep);
objp = cache_alloc_refill(cachep, flags);
}
kmemleak_erase(&ac->entry[ac->avail]);
return objp;
}这里首先涉及到我当初一直困惑的一个点:在使用 kmem_cache_create() 建立相关的管理结构之后,究竟有没有分配真正的内存空间呢?在通读了相关的代码之后,我得到了答案:没有,也没必要。因为存在这么一种情况:如果使用 kmem_cache_create() 之后还分配了真正的内存空间之后,如果该 slab 一直不使用,那么岂不是浪费了很多宝贵的内存了吗?
解决上面的这一个疑惑之后,我们就可以知道在上面的代码中,第一次我们是走 else 那个分支了,也就是调用了 cache_alloc_refill() 来分配空间:
static void *cache_alloc_refill(struct kmem_cache *cachep, gfp_t flags)
{
...
retry:
...
while (batchcount > 0) {
struct list_head *entry;
struct slab *slabp;
entry = l3->slabs_partial.next;
if (entry == &l3->slabs_partial) {
l3->free_touched = 1;
entry = l3->slabs_free.next;
if (entry == &l3->slabs_free)
goto must_grow;
}
}这里我再插一句:在 Linux 内核中的链表的实现是十分简洁优美的,它只有两个指针,并不存在数据域。这么做是为了通用性,即任何结构都可以组织自己的链表,然后在结构体中嵌入 struct list_head 即可。然后可能有人会问了,如果我有一个 struct list_head ,那么如何才能访问到该链表的起始结构呢?内核十分贴心的给我们准备了一个宏:container_of:
简单来说,这个宏的作用就是:*我有一个类型为 (type )->member 的变量,想要得到包含该变量的 type 类型变量的地址。
所以在这里,如前面所说,这里 l3 的三个链表都是连接 struct slab 类型的,而这个类型就是内存空间的真正所在,也就是我们前面所说的 2^order 个物理页组成的 slab 。
在 kmem_cache_create() 的过程中,在分配 struct kmem_list3 的时候调用了 kmem_list3_init() (line 3844) 将 l3 的三个链表全都置为首尾相连的空链表,所以上面的函数在初次运行的时候最终将跳转到 must_grow 这个标签:
must_grow:
l3->free_objects -= ac->avail;
alloc_done:
spin_unlock(&l3->list_lock);
if (unlikely(!ac->avail)) {
int x;
x = cache_grow(cachep, flag | THISNODE, node, NULL);
ac = cpu_cache_get(cachep);
if (!x && ac->avail)
return NULL;
if (!ac->avail)
goto retry;
}很明显,函数将调用 cache_grow() 来进行真正的内存分配:
static int cache_grow(struct kmem_cache *cachep,
gfp_t flags, int nodeid, void *objp)
{
...
offset = l3->colour_next;
l3->colour_next++;
if (l3->colour_next >= cachep->colour)
l3->colour = 0;
offset *= cachep->colur_off;
...
}诶,到这里,总算可以说到前面铺垫了很久的所谓的“缓存着色”了,不过我觉得我得先简单地提一下 CPU cache 的工作原理才行:
CPU cache 就是我们常看到的一级缓存,二级缓存,三级缓存啊,引入这些缓存是因为内存 RAM 的速度相较于 CPU 的速度而言,是在是太慢了,所以为了提高速度,所以 CPU 制造商提供了速度接近于 CPU 的小容量缓存,以便加速 CPU 与 RAM 的数据交换。具体的策略是:
每块 cache 会被分为更小的 cache line ,每个 cache line 的容量是一样的,然后 CPU 将虚拟地址分成三部分—— data, index, tag ,其中 data 长度是 cache line 的长度,index 的长度是 cache 的长度减去 data 的长度,最后 tag 的长度是虚拟地址的长度减去 data+index 的长度。举个例子,在 x86 的机器中,虚拟地址的地址空间是 32bit=2^32 ,假设我们的一级缓存有 4MB=2^22,cache line 的长度是 64bit=2^6 ,所以,data 就是 6 位,index 就是 (22-6) = 12 位,tag 就是 32-22=10 位。然后得到这些位之后,CPU 的每一个虚拟地址,将其分成上面的三部分之后,将按照 index 作为索引存入到 cache 中,然后在看需要的内容是否在 cache 中,这回比较需要的虚拟地址的 tag 与 cache 对应索引 index 的 tag 是否一致,如果一致说明 cache hit ,否则说明 cache miss 。
有点啰嗦,不过这些知识准备是必须的,然后我们就可以来具体阐述了。
我们在前面提到,slab 利用剩余的不足一个 object 的空间来进行缓存染色。具体说来,就是以平台的 cache line 的长度(存储在 cachep->colour_off)为偏移值(这一点非常重要!),计算出剩余的空间有多少个偏移值 cachep->colour ,然后就从 0 到 cachep->colour - 1(这个值是 l3->colour_next),每次就偏移 colour_next * colour_off 。这样,根据我们上面的叙述,每个 slab 将最终被放到不同的 cache line ,从而缓解了缓存过热的问题。
不过,如果你细心一点的话,你也可以发现,其实这个方法并不是特别的有效,因为它的有效范围只有 colour 个,也就是说,colour 个之后,还是会发生覆盖的问题,所以我在上面才用了缓解一词。
总之,上面的代码就计算了下一个偏移值 offset ,那么真正的偏移在那里呢?请看后面的代码:
if (!objp)
objp = kmem_getpages(cachep, local_flags, nodeid);
if (!objp)
goto failed;
slabp = alloc_slabmgmt(cachep, objp, offset,
local_flags & ~GFP_CONSTRAINT_MASK, nodeid);真正的页分配就在这里了—— kmem_getpages() ,而真正的偏移就在 alloc_slabmgmt() 这个函数:
static struct slab *alloc_slabmgmt(struct kmem_cache *cachep, void *objp,
int colour_off, gfp_t local_flags,
int nodeid)
{
struct slab *slabp;
if (OFF_SLAB(cachep)) {
...
} else {
slabp = objp + colour_off;
colour_off += cachep->slab_size;
}
slabp->inuse = 0;
slabp->colouroff = colour_off;
slabp->s_mem = objp + colour_off;
...
}诶,这里就可以很明显的看出来了整个 slab 的布局了:在连续页 objp 的起始,先是 colour_off 的偏移,然后是 slab 的一些管理头(管理头的大小是 cachep->slab_size),最后就是 object 的起始地址 slab->s_mem 了。
接下来的具体工作就是设置 slab 的 bufctl 控制数组,这里简单地提一下:slab 控制头有一个成员是 slabp->free ,意义是当前可用的 object 的索引,而 bufctl 控制的则是当前可用的下一个 object 的索引。
然后,新建立的 slab 加入到 l3 的 slabs_free 链表(这很重要!)。然后 cache_grow() 函数结束,返回 cache_alloc_refill() ,注意,此时我们只是分配了一个新的 slab ,还没有分配出去。具体就是在 goto retry 重新回到 cache_alloc_refill() 那里重新分配,因为此时我们的 slabs_free 已经不是空的了,所以函数接下来将 batchcount 个 object 移到 array_cache 中,然后修改 slab 的 bufctl 数组。最后,看 slab 是否所有 object 都分配完了,如果是,则移到 l3->slabs_full,否则则移到 l3->slabs_partial 。
然后,在后续的操作中,如果 array_cache 中有空间,则从其直接分配,否则就看 slabs_partial 或者是 slabs_free 是否有足够的 object ,在不然,就再次重复上面分配 slab 的操作了。
释放内存—— kmem_cache_free()
有了上面已经十分详细的阐述之后,释放内存和后面的销毁就显得简单许多了,就是从 array_cache 移回 slab 并且修改 bufctl 控制数组而已。就不赘述了。
销毁内存—— kmem_cache_destroy()
同样不赘述了。
好了,整个 slab 分配器我大概就简单地说到这里。下面我说一下我自己的看法。我们可以发现,slab 为了加快分配速度,使用了很多的管理结构,其中花销最大的就是那个 bufctl 数组,所以如果是分配小的 object 的话,那么这个 bufctl 数组占用的空间还是相当可观的。这也是它的一个主要的缺点。而后来的 slub ,就是针对这个缺点进行了有效的改进,而这,我在后面的博客中,将会详细讲解。
EOF
Author: simowce
Permalink: https://blog.simowce.com/linux-memory-managent-slab-allocator-and-kmalloc/

本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可。